Our story begins in Holland in 1997, where a researcher named Stijn van Dongen, who is pretty good at Go, has a 5-minute flash of insight into modeling flows with stochastic matrices. He writes a thesis about it and makes a toolkit called MCL with a free software license.
Flash forward to late 2011. It turns out that MCL is pretty useful if you are trying to sell home goods on the internet, and perhaps other types of goods as well. The search and recommendations team at Wayfair has just launched a simple recommender component, as described here. Our system is working pretty well and giving the people something like what they want, but we suspect we can find more interesting connections among people and things than the ones we are finding. Greg and I are reading academic and industry research papers, when Greg finds Stijn's research and MCL. We give it a try, and our recommendations improve.
That's the short version of the story. But we think it may interest some readers if we describe our thought process a little further.
There's a passage in Philipp Janert's book Data Analysis with Open Source Tools, where he's describing the state of machine learning, classification schemes in particular:
The difficulty of developing some recommendations that work in general and for a broad range of application domains may also explain one particular observation regarding classification: the apparent scarcity of spectacular, well-publicized successes. Spam filtering seems to be about the only application that clearly works and affects many people directly. Credit card fraud detection and credit scoring are two other widely used (if less directly visible) applications. But beyond those two, I see only a host of smaller, specialized applications. This suggests again that every successful classifier implementation depends strongly on the details of the particular problem—probably more so than on the choice of algorithm. (page 424)
More generally, all this machine learning, when you first hear about it, sounds as if it's going to solve all your problems by crunching unattended through a bunch of simulations, cluster-finders and test/training sequences on a big computer in your back room. But unless you're working in one of the magical domains where the textbook techniques 'just work', you're probably not going to be able to simply download a software library and plug your data in. You're going to need to get your hands into the seemingly shapeless muck, and try different approaches until you've molded it into a form where it does something useful for you. The people who won the Netflix contest had an 'everything-but-the-kitchen-sink' approach. I suspect in the end, so will we. Be warned, though: once you get past the naive approaches, you can try some very sophisticated techniques and move the needle of recommendations quality only a little. But don't be discouraged. The sense of the community, and certainly our own experience, is that with a large data set, small improvements can make a big difference in relevance and ultimately profit.
So, the kitchen sink it is. But where to start? We can't just choose our techniques at random. We need to make some educated guesses as to what might be helpful. Off to the library! Or at least the internet. There's a pretty good general discussion of advanced techniques in the recommendations space here, where the authors divide the families of approaches into the Pandora and Netflix types: content filtering and collaborative filtering, respectively. Translated into our world, let's call these Homeflix and Homedora (h/t John Mulliken for those labels). Which one? No doubt some sort of hybrid in the end, as these nice people suggest. For now let's start with collaborative filtering, so Homeflix. It would be great if we could use one of the already well-researched recommendations models based on singular value decomposition (SVD), which take explicit customer ratings of products and in some cases implicit customer preferences, to learn latent customer preferences and product attributes. Then it would just be a matter of running stochastic gradient descent or alternating least squares on top of a good linear algebra package and waiting a few hours for the customer preference and product attribute matrices to converge. Yehuda Koren and Robert Bell describe the relevant ideas in this article, which is chapter 5 of this excellent book. Something along those lines is apparently state of the art for Netflix. IBM has even worked out a way to distribute this type of work if your data is too big to fit in memory, at least for SVD models based on purely explicit ratings. But all that gives pretty poor results when we try to shoehorn our data into it.
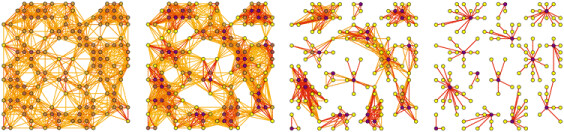
Our data just doesn't seem to be shaped like the data that works well with these approaches. How is it shaped? Well, it turns out, a lot like the proteins Stijn van Dongen was analyzing, which he depicts like so:

As you can see from that progression, he's gradually eliminating the wispy, more tenuous connections between clusters of proteins defined by the sturdier, weightier links. We need to do something a lot like that. To be specific, if you recall our definition of 'flagging' an item in the previous article, then you can model a flag as an edge of weight '1' in a graph like the one depicted.
And lo and behold, when we started recommending things based on connections as established by this process, our results improved again. Better furniture shopping through protein analysis! Who would have figured that? This is perfect for e-commerce people in a hurry. Both the science and the primary engineering (the toolkit with all its switches) are done! Greg just had to realize it would help. Of course, that's a bit of a black art in itself.
I wonder if the author of the toolkit might take a dim view of all this, based on what he says here. Where is the line between helpfully eliminating the useless irrelevant nonsense from the lists of things we present to our users, and pre-emptively discarding things they might have been interested in? We'll have to be careful about how much if any of all this we use in our internal search results, I suppose. But for showing similar items in scrollers down the page, or cross-selling at judiciously chosen spots, this will be a big help.