Introduction
If you are a Wayfair customer looking for some wall art to decorate your house, chances are you will land on our wall art SuperBrowse page (see image below or link here). This page shows a grid of 48 products, all of which are pieces of wall art. Those 48 products were chosen out of our 400k+ product wall art catalog, meaning that our first SuperBrowse page is only showing you 0.012% of all wall art sold on Wayfair. In fact, for this product class, there are ~9k SuperBrowse pages. If a person spent only 10 seconds on each page, then it would take them about 24 hours to look through our entire wall art catalog!

The above example highlights the importance of presenting our customers with products that we think they will like the best. One way to achieve this is personalization. At a high level, personalization uses data from our customers (such as the products they viewed in previous sessions), to predict which products will most interest them. This is done via complex machine learning models, such as the one described in this blog post. Every day, our customers see about 30 million products that are personalized based on their unique browsing history and several A/B tests have shown that our personalization algorithms drive significant lifts in add-to-cart and order rates, thus proving we are improving the customer’s experience by surfacing relevant products to each visitor.
Based on these results, we want to ensure we personalize the site and help customers find the products that are right for them, without spending days browsing! However, this is not always a simple task, for two main reasons. The first reason is technical: our recommendation service (see figure 2) is complex and requires several different algorithms and data sources to work together in real time (with a few milliseconds delay at most). We need to ensure pages load instantly and customers are spared those pesky loading spinners.

Figure 2: A simplified representation of the recommendation service workflow.When a customer visits a page, the following steps happen:
1. Wayfair website sends a request to the recommendation service.
2. The recommendation service requests relevant customer data be sent to model service. This happens in two steps:
a. The recommendation service sends a request to our customer information service to get the customer’s relevant information (e.g. which products the customer has seen so far)
b. It then sends another request to our model service, that hosts our machine learning models.
3. Service makes recommendations for products to show customer based on model outputs.The recommendation service then combines the output of a variety of models to create a final list of products that we want to show our customer. Any business logic is also applied at this step (e.g. removing out of stock products from the final sort).
4. Recommended products are shown to our customers.The final list of products is then passed to back to the front end of the site, which renders products on a SuperBrowse page. The entire process takes on average about 200ms.
The second reason is cultural: at Wayfair we have a culture where we move fast and are OK with (occasionally) breaking things. That means that we often have several data scientists, engineers, and Web analysts working on different parts of the recommendation system simultaneously and pushing the envelope of what can be done. So yes, we have had some mishaps in the past and it is safe to assume we will in the future as well! For this reason, monitoring the health of our recommendations is of paramount importance.
In this post, we will describe how we built an in-house anomaly detection solution to monitor a key recommendation-related KPI and ensure we deliver recommendations to our customers every day.
Building the Tool
At the simplest level, three things are needed to build an anomaly detection system. First, one needs a metric to monitor, then, a model that can distinguish between normal and anomalous behavior, and finally, a pipeline that repeatedly checks the status of our metric and alerts stakeholders if something anomalous is detected. Below, we will lead you through our process in developing these essential components.
Step One: Choosing the right metric
One of the first challenges we faced in building our anomaly detection system was deciding which metric to monitor. For the sake of simplicity, we wanted to monitor a single metric that could quickly inform us of the health of our recommendations. For some context, the final 48 products a customer sees on SuperBrowse come from different algorithms, the outputs of which we then merge to generate a final list. Only half of the products from this list come from our personalization algorithm and not all pages can be personalized; for instance, if you are a new customer, we don’t know enough about you to recommend personalized products for you.
We therefore defined a metric called recommendation throughput (R), which is defined as the sum of recommended products on a page divided by number of SuperBrowse pageloads (both personalized and non) over a certain period of time, usually one hour. (See formula below)

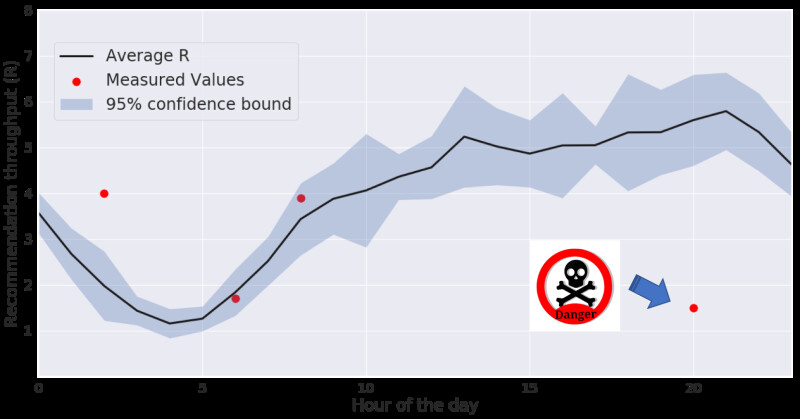
Simply, R is the average number of recommended products we show on SuperBrowse. The value of R is usually between 2 and 5, as can be seen in Figure 3.
This metric has a few advantages:
- Business growth and seasonality are factored in. If we were only monitoring the number of recommended products, this could spike because of seasonality effects (e.g. Black Friday/Cyber Monday), or simply because of our business growth. By normalizing our metric with the total number of pages, we account for this problem.
- Because we include non-personalized pages in the denominator, this allows us to flag cases in which we are not serving recommendations to a subset of pages. We have seen issues in the past on filtered pages (e.g. when a user wants to see wall art under $99) not showing recommended products at all. Our metric, as defined above, would catch that issue.
Step Two: Creating a simple anomaly detection model
Once we determined a single metric to monitor (R), the next step was to develop a model that would allow us to know what was a "normal" or "anomalous" value for R. Again, in the spirit of “not letting perfect get in the way of done,” we chose a fairly simple model. The model calculates the mean and standard deviation of R over a time period (usually a week) and identifies any value which is further than twice the standard deviation from the mean; these values are flagged as anomalous. This can be seen in Figure 3, which shows the metric as well as a 95% confidence bound around it (blue shaded area). In this example, we also show a few values for R (red dots). The value of R at 8 pm is considered anomalous, as it is outside of our confidence interval for that particular hour.

Step Three: Building a pipeline
After establishing a metric and building a simple anomaly detection model, we needed to build a pipeline that allowed us to check R at a regular cadence. To this end, we used
Airflow to build a tool that:
- Trains the model on a daily basis (by looking at historical data for R at each hour)
- Calculates R for the past hour and checks whether it is anomalous (on an hourly basis)
- Sends an email to alert stakeholders if it finds that R is anomalous at least three times in a row
Wondering why we wait for R to be anomalous three times in a row before sending an alert? We want to minimize false positives! Indeed, since we use a 95% interval and check R every hour, that means that, in a given week, we expect 8 false positives (24 (number of hours in a day) *7 (number of days in a week) * 0.05 (probability of a false positive) = 8 false positives). This may lead to alert fatigue, where alerts are ignored altogether. However, if we wait for three consecutive anomalous values for R, the number of false positives in a week (assuming each event is independent) will be 0.021 (24*7*0.05^3 (probability of 3 false positives in a row) = 0.021), a much more reasonable rate.
The anomaly detection pipeline described here has been live in production for several months, during which it has proved quite useful. In fact, coincidentally at the time of writing this blog, some routine maintenance had unintended consequences which resulted in a large drop in SuperBrowse recommendation throughput, among other things. Our tool promptly detected this drop and helped our stakeholders quickly realize that there were outstanding issues that needed to be fixed.
We are never done
One of Wayfair’s values is that we are never done and, in that spirit, we have already identified improvements to the detection system that we plan to make in the future.
- Remove bot traffic from our data: The plot of R in Figure 3 shows a clear hourly trend that resembles our overall site traffic pattern (with peaks in the afternoon/evening and a trough at night, see also Figure 1 here). After some digging, we realized that this was caused by bot traffic. Bots usually are not eligible for personalization, so at times when bot traffic is relatively higher than real traffic (such as at night, when users are usually asleep), we see fewer recommended products on SuperBrowse. This can be problematic as, if bot traffic spikes either up or down, this will affect R and trigger false alerts. We have tried removing sessions that we identified as bot traffic and indeed R shows an almost flat trend. Unfortunately, the Hive queries required for this are quite hefty (consider that this tool runs every hour!), so more work will be needed to optimize the queries.
- Reduce false alerts: Despite the strategies described above, we find that we still get a relatively large number of false alerts from the tool. We plan to tweak two parameters: the confidence interval (currently 95%) and the number of consecutive anomalous values (currently 3), to reduce false alerts.
- Send Slack channel alerts: Once we have a reasonable amount of false alerts, we also plan to have Slack alerts in engineering channels, so that we can alert a larger audience and act faster, should anything break.
This is the first post by our Web Analytics team, an 80+ people team focused on identifying strategic opportunities and driving decisions grounded in customer analytics and insights. Stay tuned for more interesting projects from this team!
